Consistency training III: An engineer's guide to the literature
You may have first seen consistency training presented alongside pretext tasks as a new and improved way of doing self-supervised learning (SSL) for computer vision. That’s just an accident of history. Pretext tasks have nothing to do with consistency training—they’re totally different. ^ You can shoehorn the concepts together. Many do. Confusing! Pretext task SSL is just supervised learning where your labels just happen to be derived from the data itself. In consistency training there are no labels, not even made-up ones. We’re not telling the model how to map inputs to outputs, we’re just telling it to map in the same way across different views.
Pretext-tasks are straightforward: make up a task for your model to do, train it in a totally supervised fashion, then throw the task head away and hope you’ve created useful features. After you’ve figured out how to derive your labels, this is just supervised learning. Folks in olden times used to do this primarily with autoencoders, but the default pretext task nowadays is Imagenet classification. ^ Pretraining on imagenet is still just a pretext task, albeit a supervised one. Sometimes you’ll see things like “SSL in computer vision can now surpass a supervised baseline” which actually means “self-supervised pretraining can sometimes beat supervised pretraining”. This is great, but it shouldn’t be that surprising—classification on a perfectly balanced dataset of strongly curated images may not be a relevant pretext task depending on the downstream application. Most computer vision research in SSL was pretext-task based until 2019.
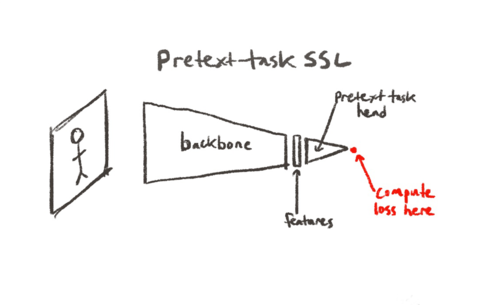
Basic pretext task phenotype. Train in a supervised fashion on actual labels or ones you made up, throw the pretext-task head away and hope you’ve created useful features. Loss happens at the targets like in normal supervised learning. Pretext task head can be doing Imagenet classification, autoencoding, solving a jigsaw task or whatever.
There are a bunch of pretext tasks to choose from. You can scramble frames in a video and put them back together, or try to generate the audio channel from the video one. You can change an image to black and white and try to recolor it. You can rotate the image and predict the rotation, or you can cut the image up into jigsaw pieces and make the model put the puzzle back together. You can make the model infill some patches you’ve blanked out or you can go all the way with an autoencoder and make the model reconstruct the entire input. ^ Not including any references here. There are hundreds of papers out there that differ only in their choice of pretext task. Google them if you’re interested.
All of those pretext tasks will make your model react differently to different views of the same data. Different rotations, jigsaw configurations, crops, etc, of the same image will give you different features.
But in reality you probably want the model to respond to different views in the same way. This is the primary motivation of invariance-based consistency training: we want our model to respond in the exactly the same way to different perturbations of the same input data. If it’s not clear why this produces useful features, check out our last post: Consistency training II: How does it work?
Not only does it feel intuitively correct that different views of the same image should produce similar features, we also see empirically that this just works better than pretext tasks.
Misra et al
Self-Supervised Learning of Pretext-Invariant Representations
(2019)
———————–
PIRL. Consistency training with NCE objective where different views are different jigsaw permutations. Motivation was to demonstrate the superiority of consistency training vs pretext tasks in a fair bake off, hence the jigsaw data aug. Consistency training wins. “Such losses encourage networkφθ(·)to learn image representations that contain information ontransformationt, thereby encouraging it to maintain infor-mation that is not semantically relevant”
and
Tian et al
Contrastive Multiview Coding
(2019)
———————–
CMC. Multi-modal contrastive learning using different color channels. “Given a dataset of RGB images, we convert themto theLabimage color space, and split each image intoLandabchannels, as originally proposed in SplitBrain autoen-coders [85]. During contrastive learning, L and ab from thesame image are treated as the positive pair, and ab channelsfrom other randomly selected images are treated as a neg-ative pair”
both showed explicitly that consistency training beats pretext task training in a fair bake-off. It’s also just plain to see in the literature: the best SSL methods have been consistency-based since 2019.
But some pretext tasks also do consistency training. The original work here is
Exemplar.
Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
(2014)
———————–
Exemplar. Early modern work that parented the following work in instance discrimination. Contrastive consistency training using a monster softmax, one output for each seed image in the dataset.
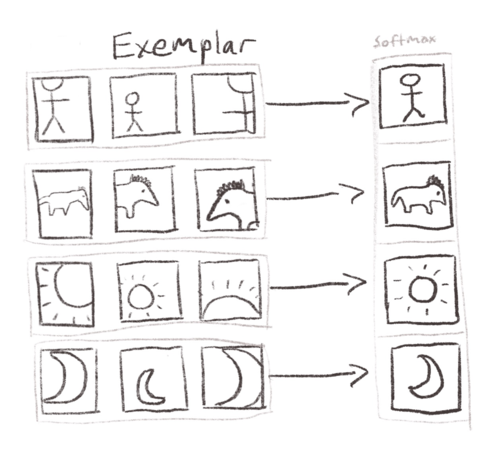
They use the pretext task of “instance discrimination”, where you treat each image in your original dataset as its own class. The model takes in differently augmented views of the data and has to map them to the original “exemplar” seed image. This makes the softmax layer as big as the original dataset itself.

This works. Mapping different views to the same seed image creates the invariances that we want. But imagine that monster softmax! It has an output neuron for every image in the dataset. Clearly not scalable.
We can just cut out the middleman. All we actually want is for different views of an image to produce the same features. That’s something we can optimize directly. We can implement our loss term directly on the features.
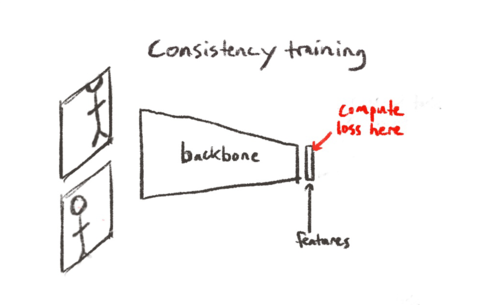
Basic consistency training phenotype. Run differently augmented views of the same data through the model and train it to output the same features for all versions.
Much more direct. We’re training exactly what we want, no pretext task apparatus to mess around with. Simple to understand, simple to code. And it actually works. This is the basic formulation of consistency training. All consistency methods follow this general format.
You can choose any loss function you want to nudge your features together. The simplest is MSE, used by
Transformation-Stability (TS)
Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning.
(2016)
———————–
“Transformation/Stability (TS)” Representative early modern work in consistency training. Horseshoe model but compares views simultaneously rather than across time.
and
Π-model (Horshoe),
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
among many others.
TS
Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning.
(2016)
———————–
“Transformation/Stability (TS)” Representative early modern work in consistency training. Horseshoe model but compares views simultaneously rather than across time.
is as simple as it gets: a single model, run two views of a single image together through the exact same model and enforce distance loss on the outputs.
Horseshoe
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
adds a bit of asymmetry: instead of comparing features at the same point in time, they compare features from this epoch to features from the previous epoch. Same model, slightly different weights.
Instead of a previous model, you can take a weighted average of previous models.
^
This is like the temporal ensembling we do for stability in supervised learning, or like what we do to smooth the bootstrapped updates from the Bellman equation in RL.
Laine and Aila’s
Temporal Ensembling model
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
takes a rolling average of predictions over time. The canonical work that we’ll see pop up most often, however, is
Mean Teacher,
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.
(2017)
———————–
Refines Laine and Aila’s EMA into Mean Teacher, the canonical example from the asymmetrical EMA siamese family. Consistency training from semi-supervised learning. Uses dropout and basic data aug.
which takes an exponentially-moving average (EMA) of model weights instead. You’ll see variants of this model everywhere:
French et al
Self-ensembling for visual domain adaptation
(2018)
———————–
Consistency training. Mean Teacher applied to domain adaptation. Suggests that the best domain-adaptation methods will probably be consistency based. Only does explicit “domain adaptation” by using adabn, everything else is just Mean Teacher from semi-supervised learning.
would use it to win the VisDA competition in domain adapaptation. Xie et al would use a version of it in
Noisy Student
Self-training with Noisy Student improves ImageNet classification
(2019)
———————–
Mean Teacher on steroids. SOTA on imagenet for a few years. Starts with a totally pretrained teacher model compared to vanilla mean teacher which trains both in tandem. Instead of an EMA teacher, periodically replaces the teacher with the student. Only does augs on the student’s data.
to hold SOTA on Imagenet for a while.
Most of the methods we’ll see in the rest of this post are variants of the two main families above: symmetrical like
TS
Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning.
(2016)
———————–
“Transformation/Stability (TS)” Representative early modern work in consistency training. Horseshoe model but compares views simultaneously rather than across time.
and
Horseshoe
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
where both lanes are identical, or asymmetric like
Mean Teacher
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.
(2017)
———————–
Refines Laine and Aila’s EMA into Mean Teacher, the canonical example from the asymmetrical EMA siamese family. Consistency training from semi-supervised learning. Uses dropout and basic data aug.
and
Temporal Ensembling.
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
Both of these are types of
siamese network.
Signature Verification using a “Siamese” Time Delay Neural Network
(1994)
———————–
One of the original works on consistency training. Introduces the siamese network. “During training the two sub-networks extract features from two signatures, while the joining neuron measures the distance be-tween the two feature vectors.” Compares two features against each other and if similar enough, they’re legit. If above a threshold then call them forgeries. Is doing contrastive learning in what would become essentially NCE
The symmetrical ones are fully weight-tied, whereas
Mean Teacher
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.
(2017)
———————–
Refines Laine and Aila’s EMA into Mean Teacher, the canonical example from the asymmetrical EMA siamese family. Consistency training from semi-supervised learning. Uses dropout and basic data aug.
and other EMA-variants are “loosely weight-tied” in the sense that their weights are similar but not identical
TS,
Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning.
(2016)
———————–
“Transformation/Stability (TS)” Representative early modern work in consistency training. Horseshoe model but compares views simultaneously rather than across time.
Horshoe
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
and
Mean Teacher
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.
(2017)
———————–
Refines Laine and Aila’s EMA into Mean Teacher, the canonical example from the asymmetrical EMA siamese family. Consistency training from semi-supervised learning. Uses dropout and basic data aug.
do MSE directly on the features. But there’s a small catch with this simple MSE loss: we’re exerting a “pull” with no corresponding “push”. There’s nothing stopping the features from collapsing into a single constant feature. Indeed, that would perfectly satisfy the MSE objective!
Exemplar
Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
(2014)
———————–
Exemplar. Early modern work that parented the following work in instance discrimination. Contrastive consistency training using a monster softmax, one output for each seed image in the dataset.
solved this with the softmax, which pushes and pulls in equal measures.
Let’s pause for a second and set the stage for the rest of this post.
We’ve already introduced the two main architectural themes used throughout consistency training: symmetric vs asymmetric. That’s not going to change. Consistency methods aren’t differentiated much by their setup. They’re all just siamese networks.
What does differentiate the work in consistency training is how they address the two major design challenges that we’ve already surfaced:
1) How do you avoid feature collapse in a scalable, memory-efficient way? E.g. Exemplar did this with a softmax.
2) How do you define different views of the data? E.g. Exemplar used crops, flips and color jitters.
Most papers in consistency training can be summed up as a response to one of those two questions. Sometimes both. It seems like SSL has been a firehose of activity recently, but in actuality more than a few of those papers—I’m just gonna say it—could have simply been tweets…
The majority of recent work addresses the first question of stability, which is mostly just a logistical problem (albeit a challenging one). The second question of defining views, on the other hand, is how we instill invariances in the model—that’s the heart of consistency training.
Avoiding feature collapse
Stable training may be just a means to an end, but that doesn’t make it easy. Like most of deep learning, it rarely “just works”. But there are a few tricks you can use to make collapse or divergence less likely.
Task signal
Most of the papers we introduced above are actually from the subfield of semi-supervised learning. They’re training a task objective at the same time as the MSE consistency loss. That makes the whole process a lot more stable. Features are less likely to collapse if they’re also being used for a supervised task.
But they can still collapse. I haven’t seen any work in semi-supervised learning that just jumps right into pure consistency training right off the bat. Most of them schedule it in only after training on the task objective for a while. This means they’ve already got a set of reasonable features before even bringing in the unlabeled data.
Horeshoe,
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
Temporal Ensembling,
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
Mean Teacher,
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.
(2017)
———————–
Refines Laine and Aila’s EMA into Mean Teacher, the canonical example from the asymmetrical EMA siamese family. Consistency training from semi-supervised learning. Uses dropout and basic data aug.
Unsupervised Data Augmentation (UDA)
Unsupervised Data Augmentation for Consistency Training
(2019)
———————–
Consistency training for semi-supervised learning using symmetrical siamese network. Not actually novel but excellent representative work, well written with great conceptual overview of how consistency training works. One of the best in the genre. Claims that their novelty is how they do data augmentation, but they do the standard set of augmentations. RandAug. “But different from existing work, we focus on the unattended question of how the form or “quality” of the noising operation can influence the performance of this consistency training framework”
and others schedule the consistency training in gradually.
Noisy Student
Self-training with Noisy Student improves ImageNet classification
(2019)
———————–
Mean Teacher on steroids. SOTA on imagenet for a few years. Starts with a totally pretrained teacher model compared to vanilla mean teacher which trains both in tandem. Instead of an EMA teacher, periodically replaces the teacher with the student. Only does augs on the student’s data.
and
Meta Psuedo Label
Meta Pseudo Labels
(2020)
———————–
Same as Noisy Student except the teacher now adapts to the student, and the teacher does consistency training ala UDA at the same time. Student trains on hard labels from the teacher.
go all the way, waiting until the teacher network is fully trained before doing any consistency training at all.
Another way these semi-supervised methods ease in the consistency signal is by only enforcing it on confident predictions. This forms a sort of curriculum. As the model gets better, it can enforce consistency on more points. As it enforces consistency on more points, the model gets better.
You may notice this sounds similar to psuedolabeling, where confident predictions are added back into the original dataset and treated as normal training data. Psuedolabelling is just consistency training where you round the softmax (i.e. do argmax to get the hard labels) and compare views across epochs like in
Horeshoe.
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
A handful of methods do this, including
Psuedolabel,
Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
(2013)
———————–
Early modern work on pseudo-labelling, i.e. semi-supervised consistency training with hard labels.
Noisy Student
Self-training with Noisy Student improves ImageNet classification
(2019)
———————–
Mean Teacher on steroids. SOTA on imagenet for a few years. Starts with a totally pretrained teacher model compared to vanilla mean teacher which trains both in tandem. Instead of an EMA teacher, periodically replaces the teacher with the student. Only does augs on the student’s data.
and
Meta Psuedo Label,
Meta Pseudo Labels
(2020)
———————–
Same as Noisy Student except the teacher now adapts to the student, and the teacher does consistency training ala UDA at the same time. Student trains on hard labels from the teacher.
but most methods use soft labels unless explicitly noted. Psuedolabelling / consistency training on the soft labels is the same as
knowledge distillation,
Distilling the Knowledge in a Neural Network
(2015)
———————–
The original work in knowledge distillation. Applied to actual Google infra.
though used for a different purpose.
Entropy minimization (entmin)
Semi-supervised Learning by Entropy Minimization
(2004)
———————–
The original work on entropy minimization, entmin, which is used often in many subsequent semi-supervised learning papers. Also later called “sharpening”. “Our proposal encompasses self-learning as a particular case, as minimizing entropy in-creases the confidence of the classifier output. It also approaches the solution of transduc-tive large margin classifiers in another limiting case, as minimizing entropy is a means to drive the decision boundary from learning examples”
operates on the same principle as consistency-training/psuedolabelling (the principle is low density separation, i.e. the “cluster assumption”) but uses a slightly different mechanism. I mention it because it shows up as an additional enhancement in a lot of the semi-supervised work. When doing entmin you punish entropy on the unlabeled points, encouraging them to coalesce into groups, which hopefully pulls them back from the “front line” of the decision boundary.
Dispersal term
Let’s move into purely unsupervised territory. The main family of methods here addresses feature collapse by adding a dispersal term to the objective function. This acts as a countervailing “push” to the “pull” of the MSE on positives we saw above. Now we’ve got two components to our objective: something like a minimization of MSE that attracts positives together, and another term to push negatives away from each other.
Noise Contrastive Estimation
The first work in consistency training for deep learning came out of
LeCun’s
Signature Verification using a “Siamese” Time Delay Neural Network
(1994)
———————–
One of the original works on consistency training. Introduces the siamese network. “During training the two sub-networks extract features from two signatures, while the joining neuron measures the distance be-tween the two feature vectors.” Compares two features against each other and if similar enough, they’re legit. If above a threshold then call them forgeries. Is doing contrastive learning in what would become essentially NCE
and
Hinton’s
Self-organizing neural network that discovers surfaces in random-dot stereograms
(1992)
———————–
The very first work using consistency training for neural networks. PDF is so old can’t even add highlights to it!
labs in the early nineties. They were both simple siamese setups—
LeCun’s work
Signature Verification using a “Siamese” Time Delay Neural Network
(1994)
———————–
One of the original works on consistency training. Introduces the siamese network. “During training the two sub-networks extract features from two signatures, while the joining neuron measures the distance be-tween the two feature vectors.” Compares two features against each other and if similar enough, they’re legit. If above a threshold then call them forgeries. Is doing contrastive learning in what would become essentially NCE
introduced the term itself. They both used what we can consider to be contrastive losses, but I’ve never seen those forms used in modern work.
^
The authors from Barlow Twins (more below) tried to get Hinton’s to work, but to no avail.
Most modern work in unsupervised consistency training that uses a contrastive loss uses some variant of the one from Radsel and Chopra in
2005
Learning a Similarity Metric Discriminatively, with Application to Face Verification
(2005)
———————–
One of the first instances of the modern NCE-like loss. Classic work applying consistency training to face identification.
and
2006,
Dimensionality reduction by learning an invariant mapping
(2006)
———————–
One of the first uses of the modern NCE loss. Consistency training with simple siamese network for the purposes of clustering and dimensionality reduction.
which is usually called something like “noise contrastive estimation” (NCE). The NCE loss is essentially similarity_of_all_positive_pairs / similarity_of_all_negative_pairs. Here’s a slightly more detailed (but still highly stylized) psuedocode description of NCE.
def NCE_loss(features_1, features_2)
""" features_1 and features_2 are differently augmented views
of the same batch. Indices are aligned, e.g. features_1[0]
and features_2[0] are from the same original image. """
batch_size, feature_dimension_size = features_1.shape
# For all pairs of points
numerator = 0
denominator = 0
for i, f1 in enumerate(features_1):
for ii, f2 in enumerate(features_2):
if i == ii:
# MAXIMIZE similarity of views from same img
numerator += cos_similarity(f1, f2)
else:
# MINIMIZE similarity of views from different imgs
denominator += cos_similarity(f1, f2)
return (numerator / denominator)Note the two components of the objective. The numerator pulls different views from the same image closer. The denominator pushes views from different images apart.
In our psuedocode above we looped through all our pairs of images. In reality, we’d compute a similarity matrix. We try to maximize the diagonal and minimize the rest.
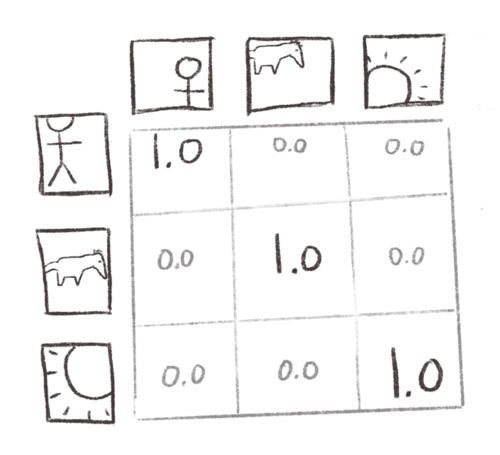
The NCE loss computes a similarity matrix between two differently-augmented views of the same underlying seed batch. We want views from the same seed image—“positives”—to be treated as identical, and views from different seed images—“negatives”—to be pushed apart.
The tough question when implementing a NCE-like loss is where you get your negatives. The dispersal term in the denominator requires a lot of negatives examples to work well. I mentioned a firehose of research—a big portion of that is just focused on how to handle the negative examples!
To address
Exemplar’s
Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
(2014)
———————–
Exemplar. Early modern work that parented the following work in instance discrimination. Contrastive consistency training using a monster softmax, one output for each seed image in the dataset.
massive softmax,
Wu et al
Unsupervised Feature Learning via Non-Parametric Instance Discrimination
(2018)
———————–
Adds a queue to get around Exemplar’s softmax. Uses NCE loss.
keep the precomputed features from all of the images in an external memory-bank and draw their negatives from there.
MoCo
Momentum Contrast for Unsupervised Visual Representation Learning
(2019)
———————–
MoCo. Just adds a queue and mean teacher style “momentum encoder” to He (_). Essentially NCE with mean teacher. Queue is to get around large batch sizes without doing a monster softmax like Exemplar.
does the same thing but using an EMA-teacher (which they call a “momentum encoder”) rather than a symmetrical siamese setup.
SimCLR
A Simple Framework for Contrastive Learning of Visual Representations
(2020)
———————–
SimCLR. Canonical work in NCE consistency training for SSL. Symmetrical siamese model.
got rid of the queue entirely, computing the NCE loss across a monster batch instead of a monster softmax. This work simplified the earlier NCE-based approaches, getting rid of the EMA-style asymmetry, the external queue, and the overengineered cropping of another earlier method,
CPC.
Data-Efficient Image Recognition with Contrastive Predictive Coding
(2020)
———————–
CPC gets upgrades.
SimCLR
A Simple Framework for Contrastive Learning of Visual Representations
(2020)
———————–
SimCLR. Canonical work in NCE consistency training for SSL. Symmetrical siamese model.
is the canonical modern work in the SSL-NCE family.
The contrastive loss isn’t limited to computer vision, but it is especially helpful for high-dimensional data like images. Consider NLP as a counterexample of a
lower-dimension, easier domain.
Yann LeCun explains why Facebook would crumble without AI
(2021)
———————–
The Robot Brains Podcast
Masked LMs can simply do a vanilla softmax over the entire vocabulary. The “generative” in GPT-3 isn’t generative at all—they’re just predicting from a predefined set of words. NCE is computer vision’s attempt to take the “contrastive-ness” benefits of the softmax and bring them into the high-dimensional realm of images.
Contrastive third party
In
Exemplar
Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
(2014)
———————–
Exemplar. Early modern work that parented the following work in instance discrimination. Contrastive consistency training using a monster softmax, one output for each seed image in the dataset.
we were able to maintain stability by doing a contrastive loss across the whole dataset. We had a softmax layer with an output activation for each image in the seed dataset and we trained the model so that different augmentations of the same seed image would light up the same activation. The NCE family solved this with by replacing the static contrastive loss of the softmax with the dynamic contrastive loss of NCE. There’s another way we can do it that allows us to keep the original softmax.
We don’t actually need to give each seed image its own personal, dedicated output neuron—all we care about is that views light up the same activation. Multiple seed images can share a single output activation. If we had a seed dataset of length 100k, for example, and we used a softmax of 1k, then each output activation would be shared by 100 seed images (assuming everything is balanced). These 100 seed images would all be using the same single activation simply as a fixed, third-party target against which to enforce consistency.
There’s an intuitive way of looking at the reduced activation space: cluster assignments. You can imagine the seed images that share an output activation also share some sort of semantically meaningful content. This is a pretext task like
Exemplar
Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
(2014)
———————–
Exemplar. Early modern work that parented the following work in instance discrimination. Contrastive consistency training using a monster softmax, one output for each seed image in the dataset.
but instead of instance discrimination we’re doing cluster discrimination.
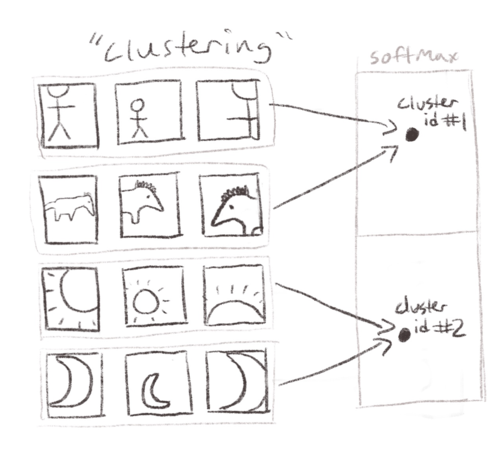
Deepcluster
Deep Clustering for Unsupervised Learning of Visual Features
(2018)
———————–
Deepcluster. Consistency training using clustering.
from Caron et al is the canonical example here. They alternate between a clustering phase where they use k-means to assign a cluster id to each record in the dataset, and a training phase where the model learns to predict the cluster ids. They compare views across time like
Horseshoe,
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
predicting previous cluster ids from current views.
Clusterfit
ClusterFit: Improving Generalization of Visual Representations
(2019)
———————–
Deepcluster but with a pretext task first. Same as Noroozi but with soft cluster assignment. Cluster based consistency training.
and
Noroozi et al
Boosting Self-Supervised Learning via Knowledge Transfer
(2018)
———————–
Consistency training with clustering. Deepcluster but first initializes with a pretext task, in this case jigsaw, whereas deepcluster simply bootstrapped from scratch. A convoluted process. First do pretext task to get the features going, then cluster based on those, then pred those hard cluster assignments as another pretext task.
do the same thing as
Deepcluster,
Deep Clustering for Unsupervised Learning of Visual Features
(2018)
———————–
Deepcluster. Consistency training using clustering.
but train on a pretext task before starting the clustering phase. This gives k-means more basis on which to cluster.
Deepcluster
Deep Clustering for Unsupervised Learning of Visual Features
(2018)
———————–
Deepcluster. Consistency training using clustering.
had to bootstrap itself from scratch—the first round of clustering would have been on the features of a randomly initialized model. After pretraining on jigsaw or rotation,
Clusterfit
ClusterFit: Improving Generalization of Visual Representations
(2019)
———————–
Deepcluster but with a pretext task first. Same as Noroozi but with soft cluster assignment. Cluster based consistency training.
and
Noroozi et al
Boosting Self-Supervised Learning via Knowledge Transfer
(2018)
———————–
Consistency training with clustering. Deepcluster but first initializes with a pretext task, in this case jigsaw, whereas deepcluster simply bootstrapped from scratch. A convoluted process. First do pretext task to get the features going, then cluster based on those, then pred those hard cluster assignments as another pretext task.
are essentially just
Deepcluster
Deep Clustering for Unsupervised Learning of Visual Features
(2018)
———————–
Deepcluster. Consistency training using clustering.
These three methods have the same problem as
Horseshoe
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
above: you have to wait an entire epoch to get your views for comparison. If your dataset is large, that means the model will have changed substantially. We need diversity of views for consistency training to work, but those views could be WAY different by the time the model gets around to the next iteration. We also don’t want our gradient update cycle to be coupled directly to the size of the dataset—how would that work with an actually massive dataset?
That’s the motivation for
SwAV,
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
(2020)
———————–
SwAV, parent of SEER, child of Deepcluster. Deepcluster but compares simultaneously within batch rather than across epoch.
the algorithm powering Facebook’s recent
SEER model,
Self-supervised Pretraining of Visual Features in the Wild
(2021)
———————–
SEER from Facebook. Swav but on bigger, non-curated data. Regnet rather than resnet.
a 1.3 billion parameter model trained on one billion uncurated images from Instagram.
SwAV
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
(2020)
———————–
SwAV, parent of SEER, child of Deepcluster. Deepcluster but compares simultaneously within batch rather than across epoch.
combines the clustering approach of
Deepcluster
Deep Clustering for Unsupervised Learning of Visual Features
(2018)
———————–
Deepcluster. Consistency training using clustering.
with the batch-level updates of the NCE-like methods above.
SwAV
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
(2020)
———————–
SwAV, parent of SEER, child of Deepcluster. Deepcluster but compares simultaneously within batch rather than across epoch.
is just
Deepcluster
Deep Clustering for Unsupervised Learning of Visual Features
(2018)
———————–
Deepcluster. Consistency training using clustering.
where you compare differently augmented views at the same time (rather than across time) and at the batch level (rather than the dataset level).
But get this: the clusters don’t even have to be learned.
SwAV
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
(2020)
———————–
SwAV, parent of SEER, child of Deepcluster. Deepcluster but compares simultaneously within batch rather than across epoch.
works almost as well using random cluster centroids. They’re just using those “centroids” as a fixed intermediary yardstick against which to measure consistency. The whole point is just to ease the contrastive challenge by avoiding the pairwise comparisons between individual points—the locations of the cluster centroids don’t matter!
^
The earlier clustering work never tests this, but the results from swav suggest that they would have gotten similar results by removing the k-means phase entirely and replacing the learned centroids with random targets.
Noise as Targets (NAT)
Unsupervised Learning by Predicting Noise
(2017)
———————–
Noise as Targets (NAT). Enforces consistency training against random fixed targets. If as many targets as images in dataset, that’s Exemplar. If fewer, that’s the clustering approaches like swav.
makes this explicit. They generate a set of targets randomly and use those as the goalposts for measuring consistency. If you set the number of targets to be the same as the size of the original dataset, that’s
Exemplar.
Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
(2014)
———————–
Exemplar. Early modern work that parented the following work in instance discrimination. Contrastive consistency training using a monster softmax, one output for each seed image in the dataset.
If you set it to less than that, it’s the clustering above but without the unnecessary centroid learning.
Explicit dispersal
The contrastive losses above are able to prevent collapse, but their mechanism of dispersal requires a comparison between every pair of points, or an extra third-party goalpost. All we want is to spread things out, so let’s just do that explicitly.
Barlow Twins
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
(2021)
———————–
Batch level consistency training like NCE family but gets dispersion by trying to set the cross-correlation matrix of two views to the identity matrix, i.e. make each pair of positive views perfectly correlated to each other and not correlated to the other images in the batch.
does batch-level consistency training like NCE but gets dispersion by trying to maximize the correlation between positives and minimize the correlation between negatives. Put another way, they encourage the model to turn the cross correlation matrix between two sets of views into the identity matrix (ones along the diagonal and zeros everywhere else). This is just like the NCE methods, but instead of a similarity matrix we’ve got a correlation matrix.
Barlow Twins tries to maximize the correlation between positives and minimize it between negatives. Like NCE but correlation instead of similarity—I even reused the same sketch!
Barlow Twins
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
(2021)
———————–
Batch level consistency training like NCE family but gets dispersion by trying to set the cross-correlation matrix of two views to the identity matrix, i.e. make each pair of positive views perfectly correlated to each other and not correlated to the other images in the batch.
encourages this decorrelation of negatives as a soft constraint, but you can also just do the decorrelation explicitly and manually like
Ermolov et al.
Whitening for Self-Supervised Representation Learning
(2021)
———————–
Consistency training. Gets dispersion uses whitening rather than negatives as in NCE. “To avoid a representation col-lapse, we do not need to contrast positives against negatives in the contrastive loss or in the triplet loss because the optimization process leads to shrinking the distance between positive pairs and, indirectly, scatters the other samples to satisfy the overall spherical-distribution constraint”
This is called “whitening”. It’s like a supercharged batchnorm: instead of just normalizing along the batch dimension you also decorrelate along the batch dimension. This does explicitly what
Barlow Twins
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
(2021)
———————–
Batch level consistency training like NCE family but gets dispersion by trying to set the cross-correlation matrix of two views to the identity matrix, i.e. make each pair of positive views perfectly correlated to each other and not correlated to the other images in the batch.
trains indirectly. They pair this “negatives-scattering” effect with a MSE loss on the positives.
Both of these methods are nice and simple. No need for massive batches. Gets right to the point.
Stopgrad, asymmetry, and hidden dispersal
When we covered the semi-supervised methods above we largely presented it as “task signal prevents collapse”. The full story is more complicated. Things will get hand-wavy here because I don’t understand the details myself.
The first confounding factor is that all of the semi-supervised methods are doing stopgrad. One of the siamese twins outputs fixed “targets” and another one optimizes towards those targets. They’re not passing gradients down both lanes at the same time like the NCE methods above. The student-teacher methods frame this explicitly as one network providing targets for another.
Implementing stopgrad is easy. Here’s the psuedocode.
# Grab two random augs of the same input batch
aug_1 = random_aug(batch)
aug_2 = random_aug(batch)
# Don't calculate gradients for one of them
with torch.no_grad():
features_1 = model(aug_1)
# DO calculate gradients for the other
features_2 = model(aug_2)
# One-way stopgrad loss.
# We could also do it the other way and add them together for a two-way loss.
loss = mse(features_1, features_2)The second candidate is asymmetry at the model level. The EMA family, for example, has one model where the weights are a moving average of the other. The asymmetry itself seems helpful, but these models also have no choice but to also do stopgrad. The offline, EMA “teacher” lane never gets gradient updates, making it hard to disentangle the effects of stopgrad and model asymmetry.
Three papers came out recently that are mostly just our familiar friends from above:
SimSiam
Exploring Simple Siamese Representation Learning
(2020)
———————–
SimSiam. ‘All you need is stopgrad + pred head.’ Vanilla consistency training. No EMA like mean teacher, just two symmetrical models like in horseshoe or transformation/stability. Applied in the unsupervised setting. Just does MSE on the features.
and
DirectPred
Understanding self-supervised Learning Dynamics without Contrastive Pairs
(2021)
———————–
Confirms SimSiam that stopgrad + pred head is all you need for stability. Proposes a method, DirectPred, that uses a non-learned something in place of the pred head, but I don’t understand what they mean. “The existence ofthe predictor and stop-gradient is absolutely essential. Re-moving either of them leads to representational collapse inBYOL and SimSiam.EMA. While the original BYOL needs EMA to work, theylater confirmed that EMA is not necessary (i.e., the onlineand target networks can be identical) if a higherαpis used.This is also confirmed with SimSiam, as long as the pre-dictor is updated more often or has larger learning rate (orlargerαp). However, the performance is slightly lower.”
are
TS
Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning.
(2016)
———————–
“Transformation/Stability (TS)” Representative early modern work in consistency training. Horseshoe model but compares views simultaneously rather than across time.
from the symmetric family.
BYOL
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
(2020)
———————–
Mean Teacher but in the semi-supervised setting and with a pred head, which is just an extra MLP on the student network to add asymmetry. Calls the siamese twins “online” and “target” rather than “student” and “teacher”. Not really “new” like the title says
is
Mean Teacher.
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.
(2017)
———————–
Refines Laine and Aila’s EMA into Mean Teacher, the canonical example from the asymmetrical EMA siamese family. Consistency training from semi-supervised learning. Uses dropout and basic data aug.
But they’re not exactly like those previous methods. They also add a bit of asymmetry in the form of an extra MLP head on whichever model is getting the gradient update.
Those three papers seemed to show that the extra MLP and stopgrad are enough to stabilize training. No need for supervisory task signal. No need for an EMA teacher. ^ BYOL initially claimed that the EMA lane was necessary because of how it stabilized the targets—same rationale as we’ve heard from the teacher student methods—but they later showed that it wasn’t actually critical, just helpful. But the MLP needs to have a higher learning rate. Why? I’m not sure.
To add to the confusion, EMA on one of the lanes may not be necessary, but it seems to be helpful. The three papers above all found it to give a small but reliable boost.
BYOL
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
(2020)
———————–
Mean Teacher but in the semi-supervised setting and with a pred head, which is just an extra MLP on the student network to add asymmetry. Calls the siamese twins “online” and “target” rather than “student” and “teacher”. Not really “new” like the title says
added it to
SimCLR
A Simple Framework for Contrastive Learning of Visual Representations
(2020)
———————–
SimCLR. Canonical work in NCE consistency training for SSL. Symmetrical siamese model.
and boosted their original performance. And there’s all the previous work in the mean teacher family that found the EMA twin to be important for SOTA performance. Even
MoCo
Momentum Contrast for Unsupervised Visual Representation Learning
(2019)
———————–
MoCo. Just adds a queue and mean teacher style “momentum encoder” to He (_). Essentially NCE with mean teacher. Queue is to get around large batch sizes without doing a monster softmax like Exemplar.
probably gets a benefit from it, though they created their EMA teacher for a different reason.
But why does changing one of the lanes to an EMA of the other help? Is it because the teacher is giving better, more stable targets as portrayed by the student-teacher methods? Or is it just because they’re different, which adds asymmetry in the same way as the mysterious pred head?
These questions also spill into the work on clustering above. You can’t pass gradients through the clustering phase—all of those papers are doing stopgrad implicitly. Is clustering just a complicated way of stopping gradients?
Deepcluster
Deep Clustering for Unsupervised Learning of Visual Features
(2018)
———————–
Deepcluster. Consistency training using clustering.
was also getting extra view diversity by waiting an entire epoch to compare views. Was it silently benefiting from this added view asymmetry in the same way as
MoCo
Momentum Contrast for Unsupervised Visual Representation Learning
(2019)
———————–
MoCo. Just adds a queue and mean teacher style “momentum encoder” to He (_). Essentially NCE with mean teacher. Queue is to get around large batch sizes without doing a monster softmax like Exemplar.
might have been?
The plot thickens further…
Everyone does batch norm, which as we mentioned above is dispersal in disguise! Does that matter? There’s no question that batch norm acts as a batch-level dispersal term (that’s literally what it does), but it’s an
open question
Understanding self-supervised and contrastive learning with ‘Bootstrap Your Own Latent’ (BYOL
(2020)
———————–
Proposes that BYOL relies on BN for hidden dispersal effect
whether or not that’s what’s providing the critical beam of support. It will probably turn out that normalization in general is important, but that the dispersal effect of batch-level normalization
may not be strictly necessary.
BYOL works even without batch statistics
(2020)
———————–
Responding to Untitled AI’s blog post. Shows that BN isn’t what makes byol work, though good norming is essential. They replace batch norm with non-batch-dependent norming for only a small hit in performance. I’m persuaded that BN is not what’s preventing collapse here, though it is acting as a dispersal term.
Also note that
Ermolov et al
Whitening for Self-Supervised Representation Learning
(2021)
———————–
Consistency training. Gets dispersion uses whitening rather than negatives as in NCE. “To avoid a representation col-lapse, we do not need to contrast positives against negatives in the contrastive loss or in the triplet loss because the optimization process leads to shrinking the distance between positive pairs and, indirectly, scatters the other samples to satisfy the overall spherical-distribution constraint”
found batchnorm alone to be insufficient for preventing collapse, they had to also add decorrelation.
These questions may be keeping researchers up at night, but for us engineers things look rosy. We may not understand exactly why these simpler methods are more stable, but it’s nice that the best-performing methods are also the easiest ones to implement.
BYOL,
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
(2020)
———————–
Mean Teacher but in the semi-supervised setting and with a pred head, which is just an extra MLP on the student network to add asymmetry. Calls the siamese twins “online” and “target” rather than “student” and “teacher”. Not really “new” like the title says
SimSiam,
Exploring Simple Siamese Representation Learning
(2020)
———————–
SimSiam. ‘All you need is stopgrad + pred head.’ Vanilla consistency training. No EMA like mean teacher, just two symmetrical models like in horseshoe or transformation/stability. Applied in the unsupervised setting. Just does MSE on the features.
DirectPred,
Understanding self-supervised Learning Dynamics without Contrastive Pairs
(2021)
———————–
Confirms SimSiam that stopgrad + pred head is all you need for stability. Proposes a method, DirectPred, that uses a non-learned something in place of the pred head, but I don’t understand what they mean. “The existence ofthe predictor and stop-gradient is absolutely essential. Re-moving either of them leads to representational collapse inBYOL and SimSiam.EMA. While the original BYOL needs EMA to work, theylater confirmed that EMA is not necessary (i.e., the onlineand target networks can be identical) if a higherαpis used.This is also confirmed with SimSiam, as long as the pre-dictor is updated more often or has larger learning rate (orlargerαp). However, the performance is slightly lower.”
Barlow Twins
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
(2021)
———————–
Batch level consistency training like NCE family but gets dispersion by trying to set the cross-correlation matrix of two views to the identity matrix, i.e. make each pair of positive views perfectly correlated to each other and not correlated to the other images in the batch.
and
Ermolov et al
Whitening for Self-Supervised Representation Learning
(2021)
———————–
Consistency training. Gets dispersion uses whitening rather than negatives as in NCE. “To avoid a representation col-lapse, we do not need to contrast positives against negatives in the contrastive loss or in the triplet loss because the optimization process leads to shrinking the distance between positive pairs and, indirectly, scatters the other samples to satisfy the overall spherical-distribution constraint”
are all easier to code and train, and appear to be just as powerful as the more complicated methods above.
Defining views
Everything we’ve done so far assumes we have enough distance between our views. If we fed the same exact image to the same network twice in a row we’d have no signal for consistency training. We’ve already seen that asymmetric model architecture can create diversity in our views, but it gets more interesting than that.
There are two broad ways we can widen the distance between views even further: (1) we can perturb the model itself, like by using dropout, or (2) we can apply data augmentations to the inputs before they even hit the model. In reality, pretty much everyone uses dropout. All the action is in intentionally defining views through data preparation.
Model noise
Even the architecturally-symmetrical siamese models above become asymmetric when we use dropout. A few “early-modern” consistency methods rely solely on this form of asymmetry to create different views.
The first in this line was
Psuedo-ensemble,
Learning with Pseudo-Ensembles
(2014)
———————–
Early modern work in consistency training. Implements different views with different “child networks”, which appear to be just dropout. Also does entmin.
which phrases it as “taking different child networks from the main parent network” but appears to be essentially doing dropout. Laine and Aila’s
Horseshoe and Temporal Ensembling models
TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
(2016)
———————–
Canonical work in early modern consistency training for semi-supervised learning. The horseshoe model is the classic symmetrical siamese setup while the EMA model is precursor to Mean Teacher.
use only dropout, as well.
Adversarial Dropout Regularization
Adversarial Dropout Regularization
(2017)
———————–
Uses dropout for consistency training. Instead of statistical metric like NCE it learns the distance adversarial.
applies dropout-based consistency training to domain-adaptation in the same way as above, but instead of enforcing a statistical metric like MSE or NCE, they train an adversary to maximize the distance between views under different dropouts. They train this in the traditional GAN fashion, alternating between an encoder that tries to create dropout-invariant features and a discriminator that tries to differentiate between the views.
^
This seems over-engineered, but then again folks in domain adaptation have found that learned distances (i.e. adversarial training) can be more powerful than statistical metrics (e.g. MMD and CORAL) for aligning domains, so maybe it works for views as well? Saito only benchmarks against other work within the narrow subfield of domain adaptation, so we don’t know how it performs against most of the other techniques we’ve reviewed so far. What we do know is that it was defeated by the simpler approach of French et al, which was just Tarvainen’s Mean Teacher applied to domain adaptation
Data augmentation
As we talked about in the intro, our entire motivation for consistency training is that we as domain-experts have a specific set of invariances we want to intentionally impart on the model. Defining our views through data augmentation or other transformations is precisely how we inject this supervision into the algorithm. We’re sketching out zones of invariance, and our pencil is data augmentation. Everything we did in the stability section above was just a vehicle for delivering the payload we care about: consistency across views.
Standard set of augmentations
Some authors do a good job of thinking through which priors they’re imposing on the model. But a lot of the literature glosses over the specific choice of augmentation as just an afterthought.
They generally implement some variant of the augs used by
SimCLR:
A Simple Framework for Contrastive Learning of Visual Representations
(2020)
———————–
SimCLR. Canonical work in NCE consistency training for SSL. Symmetrical siamese model.
Take a random patch of the image, resize it to your target dimensions, do a random horizontal flip, do a color distortion phase composed of random combination of brightness, contrast, hue, saturation and maybe grayscaling, then finish up with random gaussian blur and maybe solarization.

The set of augmentations tested by SimCLR. They found crop + color jitter to be the most effective.
Some methods mix this up a bit but still essentially just do standard data augmentation.
SwAV
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
(2020)
———————–
SwAV, parent of SEER, child of Deepcluster. Deepcluster but compares simultaneously within batch rather than across epoch.
takes multiple crops at different resolutions rather than two at the same resolution, imparting a nice scale invariance to the model.
UDA
Unsupervised Data Augmentation for Consistency Training
(2019)
———————–
Consistency training for semi-supervised learning using symmetrical siamese network. Not actually novel but excellent representative work, well written with great conceptual overview of how consistency training works. One of the best in the genre. Claims that their novelty is how they do data augmentation, but they do the standard set of augmentations. RandAug. “But different from existing work, we focus on the unattended question of how the form or “quality” of the noising operation can influence the performance of this consistency training framework”
does RandAugment.
MixMatch
MixMatch: A Holistic Approach to Semi-Supervised Learning
(2019)
———————–
Consistency training for semi-supervised learning. Uses symmetrical siamese network. Also adds in entmin. Novel in that it uses Mixup in addition to standard data aug to get views.
adds mixup.
FixMatch
FixMatch, Simplifying Semi-Supervised Learning with Consistency and Confidence
(2020)
———————–
FixMatch first generates pseudo-labels using the model’s predictions on weakly-augmented unlabeled images. For a given image, the pseudo-label is only retained if the model produces a high-confidence prediction. The model is then trained to predict the pseudo-label when fed a strongly-augmented version of the same image.
does a weak augmentation (flip and shift) as a target, then trains towards that using strong augmentation (full set of augmentations), mimicking the benefits of a teacher network as a provider of stable targets.
PIRL
Self-Supervised Learning of Pretext-Invariant Representations
(2019)
———————–
PIRL. Consistency training with NCE objective where different views are different jigsaw permutations. Motivation was to demonstrate the superiority of consistency training vs pretext tasks in a fair bake off, hence the jigsaw data aug. Consistency training wins. “Such losses encourage networkφθ(·)to learn image representations that contain information ontransformationt, thereby encouraging it to maintain infor-mation that is not semantically relevant”
shuffles the image jigsaw-style to do a fair bake-off with old-school pretext task training. The original work in consistency training from
Becker and Hinton
Self-organizing neural network that discovers surfaces in random-dot stereograms
(1992)
———————–
The very first work using consistency training for neural networks. PDF is so old can’t even add highlights to it!
simply takes neighboring crops.
Interestingly,
BYOL
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
(2020)
———————–
Mean Teacher but in the semi-supervised setting and with a pred head, which is just an extra MLP on the student network to add asymmetry. Calls the siamese twins “online” and “target” rather than “student” and “teacher”. Not really “new” like the title says
even brags that their setup is “robust to data aug”, which is essentially saying they don’t have fine-grained control over how their data augmentations create invariances in their features.
The literature is able to treat the specific choice of data-aug as an afterthought because they’re mostly all focusing on the same set of object-recognition tasks. This isn’t a bad thing—it’s helpful to have common benchmarks—but it does mean that we need to take their perspectives with a grain of salt. Invariance across crops, for example, collapses all information relating to the global structure of an image. This particular invariance is great for Imagenet classification but it may not be what you want in your actual, real-life project. Like we saw with the hotdog example in the intro, you have to be very careful about what axes you choose to randomize—your model will become blind to them.
Getting creative
There are a few interesting exceptions to the vanilla data-aug crowd
Virtual Adversarial Training (VAT)
Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning.
(2017)
———————–
Consistency training but learns the perturbations. Like Goodfellow (2015)’s adversarial training but enforces consistency with the unaugmented view rather than class label.
learns the perturbation adversarially. Like normal adversarial training, it learns an augmentation that most messes with your objective, whereas vanilla data aug exerts the same “smoothing” pressure in all directions. This is a cool idea, but it essentially outsources the opportunity for extra supervision to an adversary. What’s preventing the adversary from making the image unrecognizable even to us as domain experts, instilling invariances we don’t want? Indeed, you have to explicitly reign in the amount of augmentation or the adversary will completely obscure the most relevant features of the input.

UDA
Unsupervised Data Augmentation for Consistency Training
(2019)
———————–
Consistency training for semi-supervised learning using symmetrical siamese network. Not actually novel but excellent representative work, well written with great conceptual overview of how consistency training works. One of the best in the genre. Claims that their novelty is how they do data augmentation, but they do the standard set of augmentations. RandAug. “But different from existing work, we focus on the unattended question of how the form or “quality” of the noising operation can influence the performance of this consistency training framework”
would later show that the standard suite of data augmentations works better than cleverly trying to learn the augmentations.
Another interesting example of view creation is
UDA
Unsupervised Data Augmentation for Consistency Training
(2019)
———————–
Consistency training for semi-supervised learning using symmetrical siamese network. Not actually novel but excellent representative work, well written with great conceptual overview of how consistency training works. One of the best in the genre. Claims that their novelty is how they do data augmentation, but they do the standard set of augmentations. RandAug. “But different from existing work, we focus on the unattended question of how the form or “quality” of the noising operation can influence the performance of this consistency training framework”
applied to NLP, which uses back-translation to get a different view of the same underlying sentence. They outperformed previous work by a large margin using consistency training rather than a masked LM (which is contrastive but not consistency). GPT-3 would of course come in and dominate NLP with a traditional masked LM, but one wonders how a consistency approach like
UDA
Unsupervised Data Augmentation for Consistency Training
(2019)
———————–
Consistency training for semi-supervised learning using symmetrical siamese network. Not actually novel but excellent representative work, well written with great conceptual overview of how consistency training works. One of the best in the genre. Claims that their novelty is how they do data augmentation, but they do the standard set of augmentations. RandAug. “But different from existing work, we focus on the unattended question of how the form or “quality” of the noising operation can influence the performance of this consistency training framework”
would perform if it too had 175 billion parameters?
CPC
Representation Learning with Contrastive Predictive Coding
(2018)
———————–
CPC. Consisteny training for SSL. Uses complex gridification for crops.
and its
follow-up
Data-Efficient Image Recognition with Contrastive Predictive Coding
(2020)
———————–
CPC gets upgrades.
proposed a more complicated version of cropping. They divide each image into a grid of patches, run them through the model separately, and predict patches below only using the context from above.
SimCLR
A Simple Framework for Contrastive Learning of Visual Representations
(2020)
———————–
SimCLR. Canonical work in NCE consistency training for SSL. Symmetrical siamese model.
thankfully then showed that this was too clever by half—random cropping on the input image itself works better!
Different versions
Sometimes your dataset already has the multiple views you need. You don’t have to do augmentation here because you’ve already got natural groupings in the data.
Face detection is a good example. A positive set of views is all the pictures of the same person from different angles, in different lighting and in different settings. You can imagine Facebook does something like this to navigate their gigantic database of photos. There are more recent efforts on this front but they aren’t conceptually different from the classic work out of
LeCun’s
Learning a Similarity Metric Discriminatively, with Application to Face Verification
(2005)
———————–
One of the first instances of the modern NCE-like loss. Classic work applying consistency training to face identification.
and
Hinton’s
Neighbourhood Components Analysis
(2004)
———————–
Early work in consistency training, applied to face detection. Does rotation and blur for augmentations. Uses contrastive loss.
labs.
The
original siamese work
Signature Verification using a “Siamese” Time Delay Neural Network
(1994)
———————–
One of the original works on consistency training. Introduces the siamese network. “During training the two sub-networks extract features from two signatures, while the joining neuron measures the distance be-tween the two feature vectors.” Compares two features against each other and if similar enough, they’re legit. If above a threshold then call them forgeries. Is doing contrastive learning in what would become essentially NCE
does the same thing for signature verification.
^
They trained an adorable model of a few thousand parameters on two hundred signatures from their colleagues at Bell Labs. This may have been a seminal work in consistency training but apparently folks weren’t taking it too seriously—’Mickey Mouse’ showed up in the signatures at least once.
In face detection and signature verification, the invariant features are the deliverables themselves. You can use them directly to identify faces or to check signature fraud. No downstream task, just a nice set of reusable features that you can use for doing lookups. Like we mentioned above, the form of the contrastive loss means you can add new signatures or faces to your database as they come in, no fixed softmax.
Different modalities
Instead of perturbing the same set of input properties in multiple ways, you could split your input properties into disjoint sets of features. This could be color channels in an image, different columns in tabular data, or entirely different modalities like audio, text or images. These are identical to the unimodal examples above, the only difference is in how they grab their views. Most use the NCE loss or something like it.
Contrastive Multiview Coding (CMC)
Contrastive Multiview Coding
(2019)
———————–
CMC. Multi-modal contrastive learning using different color channels. “Given a dataset of RGB images, we convert themto theLabimage color space, and split each image intoLandabchannels, as originally proposed in SplitBrain autoen-coders [85]. During contrastive learning, L and ab from thesame image are treated as the positive pair, and ab channelsfrom other randomly selected images are treated as a neg-ative pair”
is of the same lineage as the
SimCLR
A Simple Framework for Contrastive Learning of Visual Representations
(2020)
———————–
SimCLR. Canonical work in NCE consistency training for SSL. Symmetrical siamese model.
crowd but uses different color channels for their different views.
^
This is a fun idea, but it makes you wonder: what invariance were they hoping to impart? In a real project, for example, if you decide that color isn’t important for your task then you just collapse your image to grayscale as a preprocessing step. No need to go through all the trouble of setting up invariance training if you can just remove the variability manually.
There’s a lot of work going under the banner audio-visual correspondence (AVC) that does cross-modal consistency training using the audio and visual channels of video. This includes
XDC,
Self-Supervised Learning by Cross-Modal Audio-Video Clustering
(2020)
———————–
Audio visual cross-modal consistency training. Novel in that they use clustering on the audio channel. Essentially a multimodal deepcluster.
which is essentially a multimodal
Deepcluster.
Deep Clustering for Unsupervised Learning of Visual Features
(2018)
———————–
Deepcluster. Consistency training using clustering.
In addition to the consistency training,
Objects that Sound
Objects that Sound
(2018)
———————–
Multimodal consistency training, audio and visual.
splits the image into a grid of small patches and scores them separately. This allows them to predict which items in a given image are making a sound.

OpenAI’s CLIP
Learning Transferable Visual Models From Natural Language Supervision
(2021)
———————–
CLIP from OpenAI. Standard consistency training using the NCE loss in a cross-modal setting, text and images. Trained on a large dataset of internet images and their corresponding captions. NCE objective gives ability for cross modal lookup, allowing a zero-shot classifier similar to the earlier work on siamese networks for face and signature verification. CLIP is a scaled up version of Con-VIRT (Zhang et al., 2020),
is the most splashy and impressive from a long line of work doing multimodal consistency training between text and image. Like the student teacher methods above, they frame this as “text giving supervisory signal to images”, but in reality they propagate gradients down both models. No stopgrad. Once trained, this lookup between text and images gives them the ability to create what they call a “zero-shot classifier”, which is just the dynamic lookup that a NCE-style contrastive loss gives you. Exactly as we’d hope,
CLIP
Learning Transferable Visual Models From Natural Language Supervision
(2021)
———————–
CLIP from OpenAI. Standard consistency training using the NCE loss in a cross-modal setting, text and images. Trained on a large dataset of internet images and their corresponding captions. NCE objective gives ability for cross modal lookup, allowing a zero-shot classifier similar to the earlier work on siamese networks for face and signature verification. CLIP is a scaled up version of Con-VIRT (Zhang et al., 2020),
develops multi-modal neurons which, for example, light up in the say way for both the text “Lady Gaga” and for images of Lady Gaga herself.
Next post: Consistency training IV: Beyond invariance
Previous post: Consistency training II: How does it work?